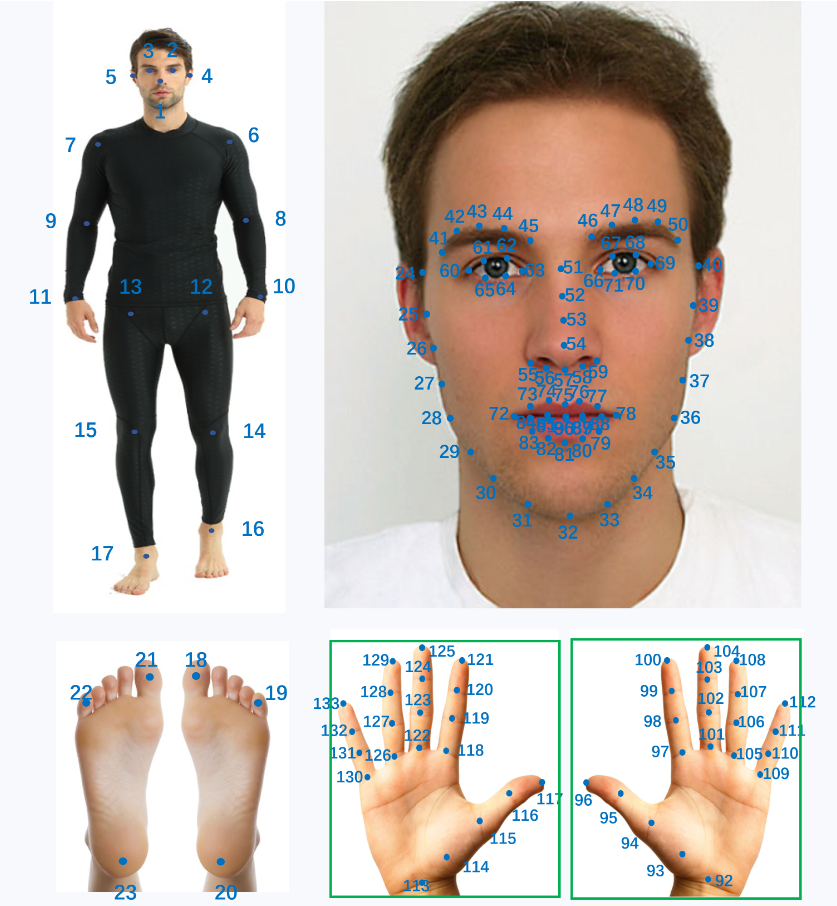
SDPose 是一种最先进的姿态估计模型,它利用了来自 Stable Diffusion 的强大视觉先验,在跨分布(OOD)场景中实现了卓越的性能。该模型变体估计 133个全身关键点,包括身体、手、脸和脚。
模型架构
SDPose 采用了一个使用 Stable Diffusion v2 权重初始化的 U-Net 主干,结合了一个专门的热图头用于关键点预测。该模型以自顶向下的方式工作:
- 人物检测:使用对象检测器(例如 YOLO11-x)检测人体边界框
- 姿态估计:裁剪并估计每个检测到的人物的17个身体关键点
- 热图生成:生成置信度热图以进行精确的关键点估计
模型规格:
- 主干:Stable Diffusion v2 U-Net(微调;架构变化最小)
- 头部:定制的热图预测头
- 输入分辨率:1024×768(高×宽)
- 输出:133个关键点热图 + 带置信度分数的坐标
- 框架:MMPose

